How to Fix the Issue of Extra Rows of Bad Data being created When Loading a Folder of CSV Files into Power BI:
Recently, I encountered an issue while working on a data project that involved loading millions of rows of data from a folder of CSV files into Power BI. During the process, I noticed that extra rows, which did not exist in the original files, were being generated. Here are the details (this is a demo project, and all sensitive information has been removed for confidentiality):
Testing with a Single CSV File
To troubleshoot and demonstrate the issue quickly, I started by testing with a single CSV file. Upon loading this file into Power BI, I noticed an error in the “Creation_date” column. The error affected less than 1% of the rows, showing an “Error” message in that column.
Initially, I assumed it was a common issue with formatting datetime values in Power BI. To resolve it, I attempted the three standard methods for converting the column to a datetime format. However, the error persisted despite these efforts.
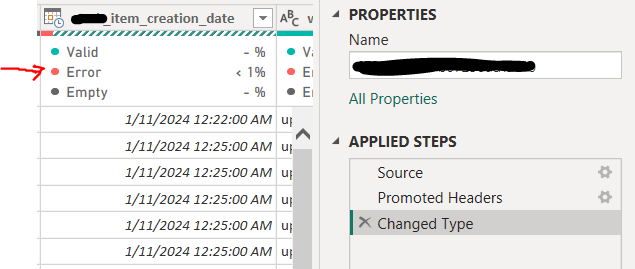
Then, I filtered the column to display only the rows with "Error," but this didn't provide much insight into the root cause of the issue.
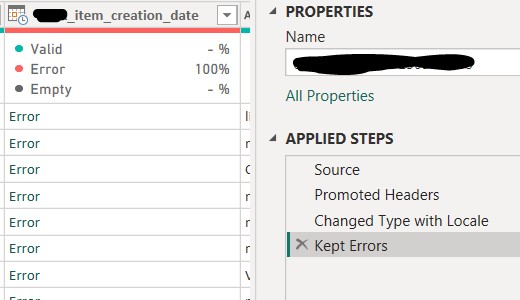
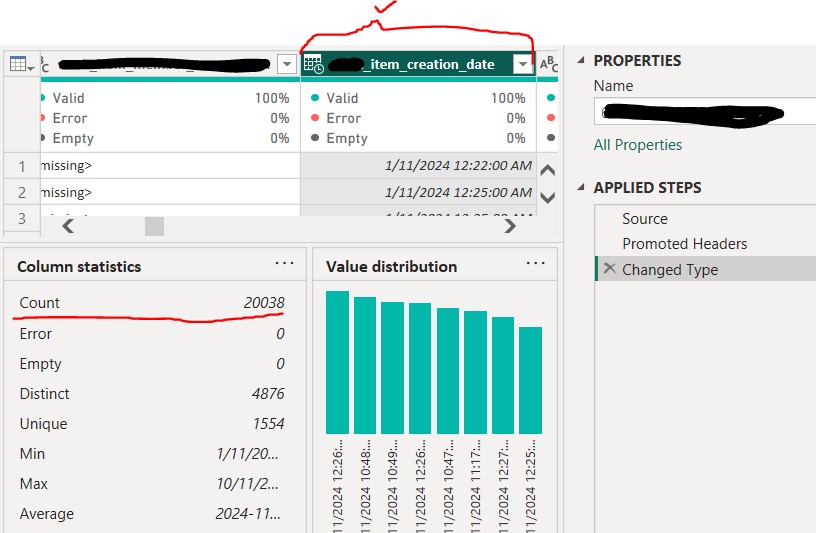
Thus, I removed the "Changed Type" step and converted the column to a "Text" data type. This should have resolved the error, but instead, I discovered "Empty" values in the column (as shown below). However, based on the context of this project, there should not be any empty values in the "Creation_date" column—every row is expected to contain a valid date. This inconsistency seemed unusual.
To investigate further, I needed to confirm whether there were indeed empty values in the "Creation_date" column. Interestingly, other columns still contained data in rows where the "Creation_date" column was empty, which, based on my intuition, indicated something was not correct.
Because of the massive size of the CSV file, I typically prefer using Python Pandas for a quick check of the values. Pandas is much faster when working with large datasets compared to Power BI or Excel.
I ran a script in Pandas to verify if there were any empty values in the “Creation_date” column. Here is a screenshot of the code. The first result returned False, indicating that there were no empty values in the column. This outcome directly contradicted the result I observed in Power BI.
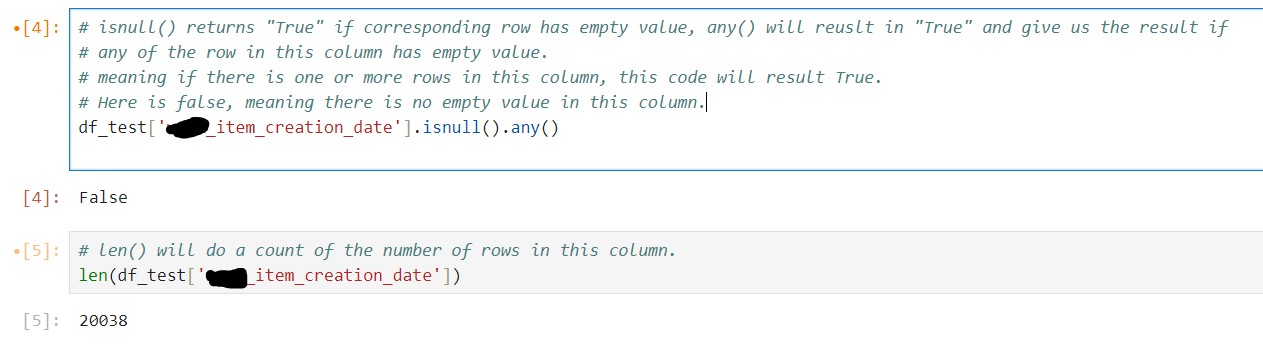
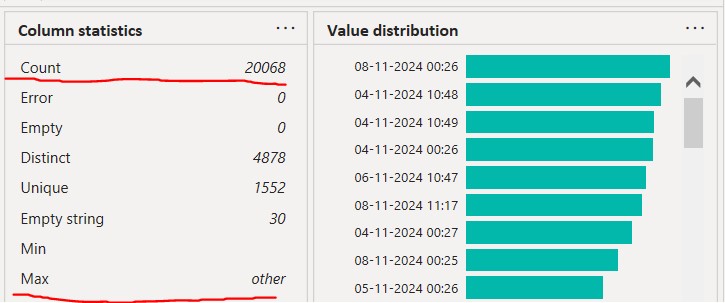
To continue debugging, I used a second Python method to check the total number of rows in the “Creation_date” column by using len(). The result showed that this column contained 20,038 rows in the test CSV file.
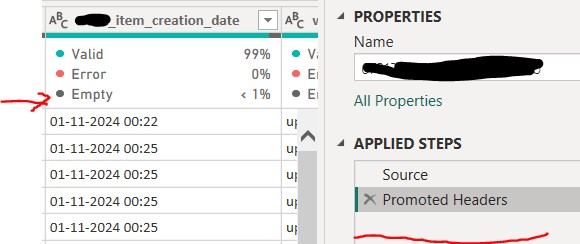
I then returned to Power BI to compare the row count. According to the Column Statistics in Power BI, the “Creation_date” column contained 20,068 rows—30 more than the Python Pandas test results. Given the context of this project, the results from the Python Pandas test were more reliable and consistent, indicating that Power BI was somehow introducing extra rows while loading the CSV file. This strongly suggested an issue with how Power BI handled the CSV file during the loading process, resulting in the creation of additional rows of data in the Query Editor. Clearly, this needed to be resolved.
To dig deeper into the issue, I began by searching online for possible explanations. While I found some discussions about similar issues, there were no definitive solutions or detailed explanations—not even from our all-powerful AI, ChatGPT! After further manual exploration in various technical forums, I came across a mention of “Line Breaks” in CSV files as a potential cause. Although the explanation was brief, it sparked an idea.
Even though rows in the “Creation_date” column showed empty values, the corresponding rows in other columns still contained data, which I realized could be leveraged to debug the issue further.
I copied the values from Power BI and analysed them in the Python Pandas test project. Upon further inspection, I discovered that one column contained a long string of text value with a sentence that included a “line break” within it.
To understand this issue better, I searched more about this topic using AI tools, and here is the explanation I found:
Quoted line breaks occur when a line break (a new line) is included within a quoted field in a CSV file. This can happen when the data within a field spans multiple lines but is enclosed in quotation marks. In following example, the “Notes” field for John Doe contains a line break within the quoted text.

With the right direction and some additional searching, I found the solution. When Power BI or other data processing tools encounter line breaks within text values, they might misinterpret these as the start of a new row, resulting in extra rows being added to the dataset.
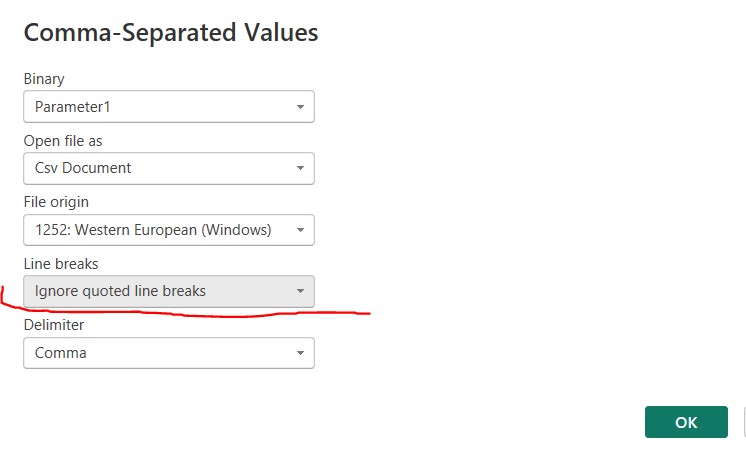
To resolve this issue in Power BI, I needed to modify the settings in the “Source” step. By clicking on the “Source” step, a popup table appeared, where I manually selected the option “Ignore quoted line breaks.” This setting ensures that line breaks within quoted text are treated as part of the same value, rather than as new rows. By default, Power BI applies the setting “Apply all line breaks,” which caused the problem in this case. (see following screenshot).

After applying this fix, the issue was resolved, and the dataset loaded correctly without any extra rows.
Once the configuration was corrected, I reapplied the “DateTime” formatting to the “Creation_date” column. This time, there were no errors, and the total row count was accurately displayed as 20,023, matching the expected result shown in Python Pandas test project.
This confirmed that the issue had been fully resolved, ensuring both data integrity and proper formatting in Power BI.
However, the above solution was applied to just one test file. I had hundreds of similar CSV files from the past several months that required analysis. To address the issue for the entire folder of CSV files, I used the following approach:
The root cause of the issue is that some fields in the CSV files contain data spanning multiple lines but are enclosed in quotation marks. Here is how I fixed the issue when loading a folder of CSV files:
Load the Folder of CSV Files
(Since this is a common method anyone can found in Youtube, I won’t re-explain the steps here.)Transform the Sample File
On the left-hand side of the Power BI interface, click “Transform Sample File.” This step ensures that changes made to the sample file are automatically applied to all the files in the folder
- Then click this “gear” icon to config the “Source”:
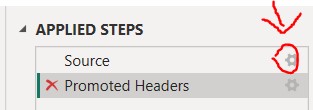
- Choose the following option to “Ignore quoted line breaks”, back to the table, this is already fixed now.
To summary, using different data tools enhances both efficiency and accuracy by allowing you to leverage the strengths of each tool. Tools like Python for quick data manipulation, Power BI for visualization, and Excel for detailed analysis enable faster processing, reduce human error, and improve the reliability of results. By choosing the right tool for each task, you can optimize workflows and achieve more precise outcomes.