This post details how to deploy your own private local AI assist on your own PC using Ollama and open-webui without inernet connection.
- - - Example – AI Assistant like this - - - - - - - ->
- - - Details for each steps - - - - - - - ->
1. Go to the offical website in Ollama and click “Download” to chose the right version to download according the system of your PC.
2. Using following Terminal Command to check if you’ve installed successfully, my is windows so I’m using Command Prompt as example.
- if it shows a version then you installed successfully.
1 | >>ollama --version |
3. Typing following command to check what kinds of operations you can do with ollama now
1 | >>ollama --help |
4. Now you shouldn’t have any LLM (large language model) installed yet.
You can check what LLM models you want to download from this link Ollama Models. Thus you can download an example model first by typing following command for instance to download this gemma:2b to your local PC (gemma is latest model series released by Google and 2B means 2 billion parameters, which is lightweight anyway)
1 | >>ollama pull gemma:2b |
5. Run following code to check if you’ve downloaded successfully
I’ve already downloaded a number of models
1 | >>ollama list |
6. In the terminal window you can use “ollama run gemma:2b” command to start using this model.
1 | >>ollama run gemma:2b |
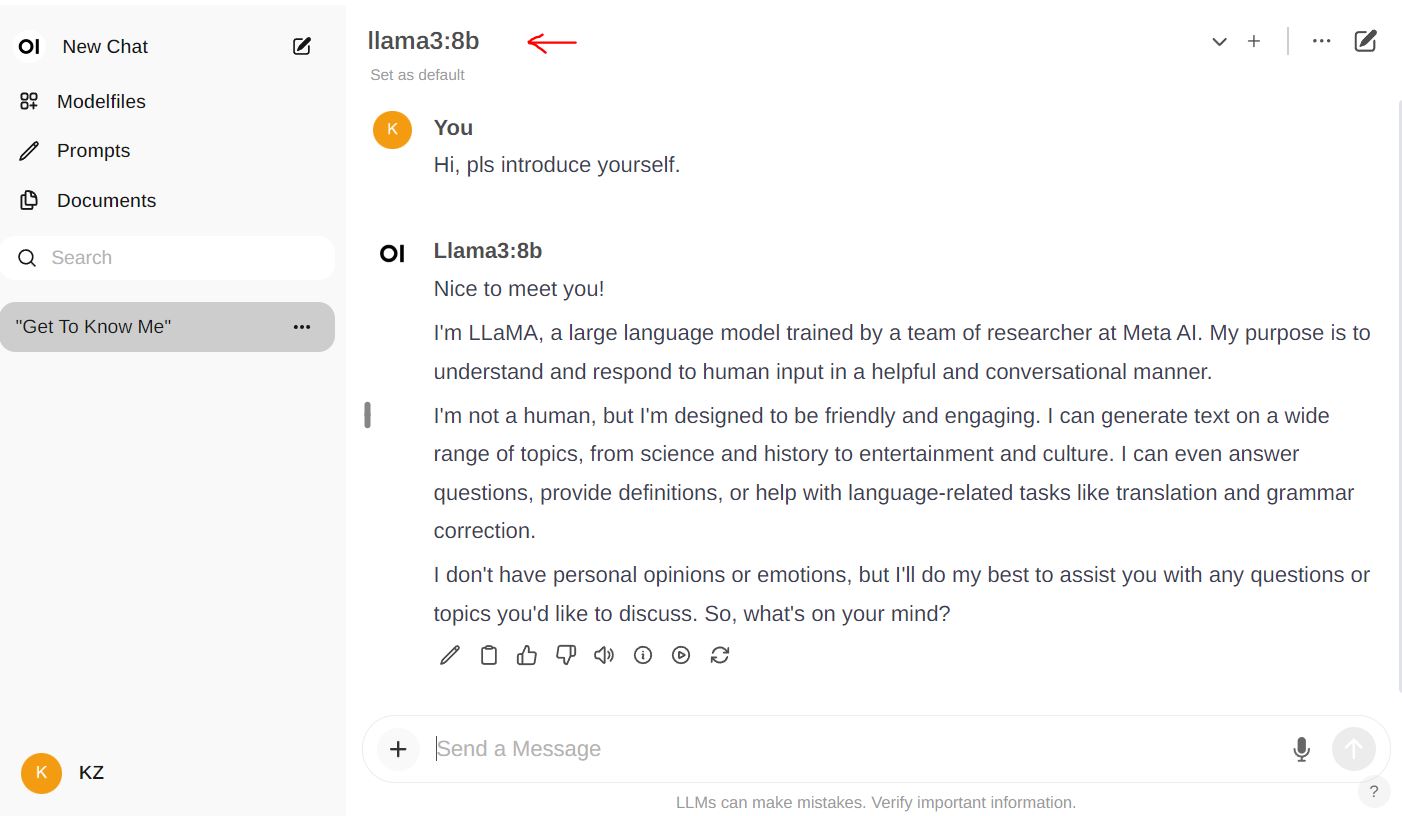
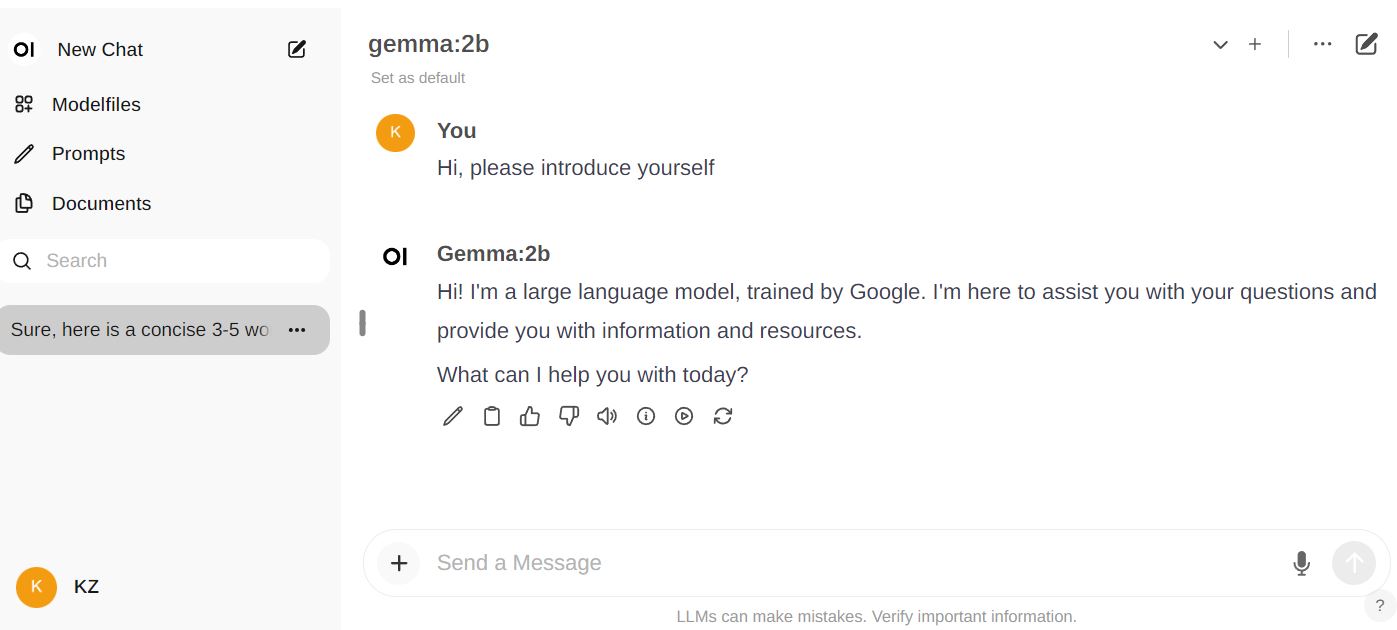
7. However I believe you wouldn’t like to using Terminal window to chat with AI, thus we shuold use somthing like this, which is called open-webui
8. Click the link of open-webui for installation guide, however you need to use Docker to install, pls using this linke to install Docker first Docker. There are tons of online tutorial to install docker, pls check youtube
9. Once installed docker you can use following command to install this “open-webui” docker image
1 | docker run -d -p 3000:8080 --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main |
10. Then open the docker desktop to check you’ve already installed open-webui
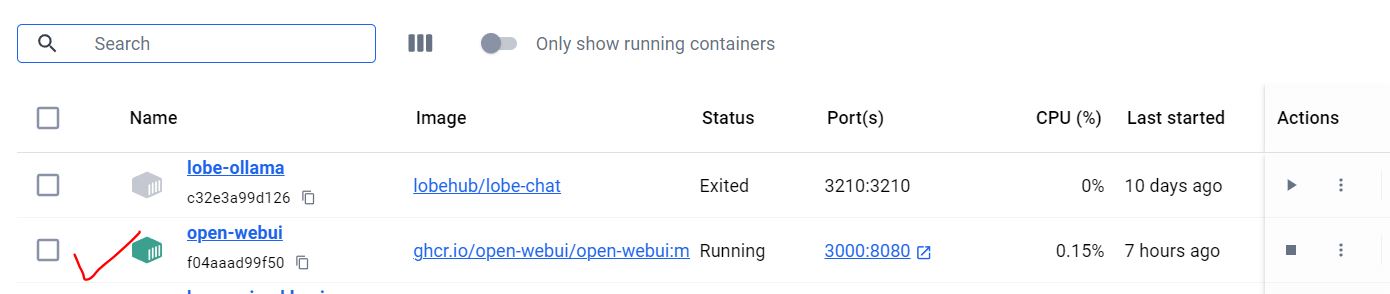
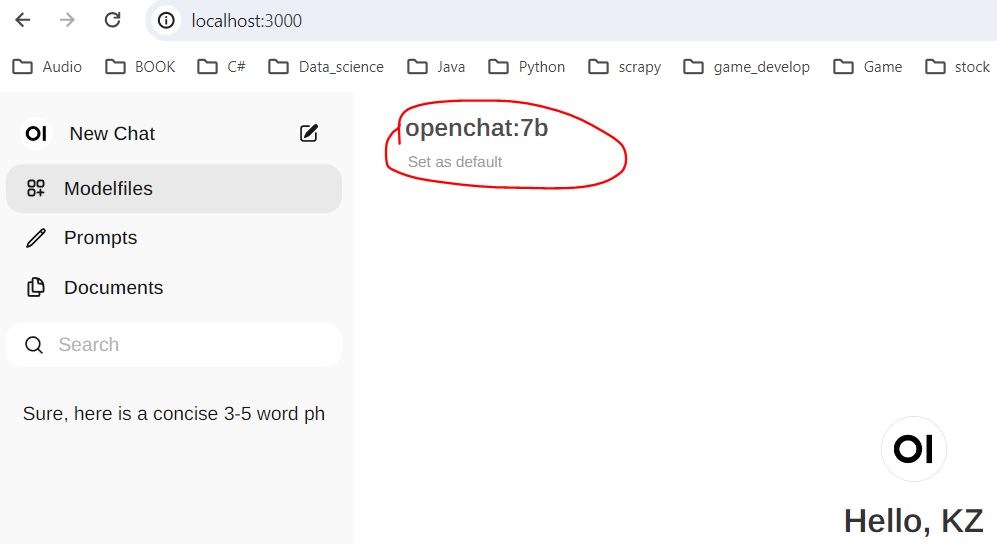
11. Open your web browser to this address http://localhost:3000/, then you are in your own private chat
- Click following red area to change to another LLM model if like.
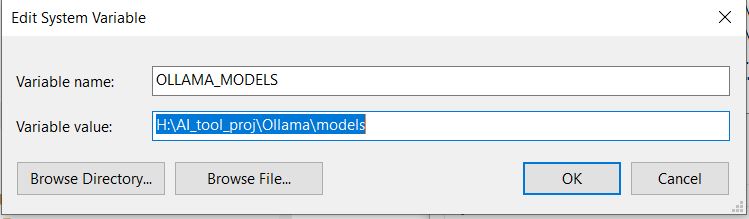
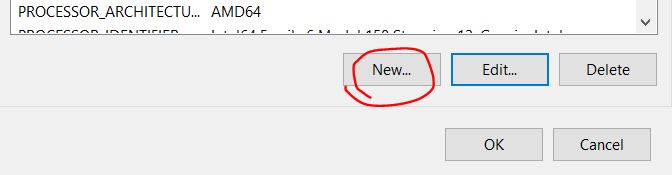
12. One imporant note for windows user if you want to download the models to another drive rather than C: Drive because Ollama defaults to download to C:
- You need to create new system variable in the “Environment Variables”.
- Add new variable with following name and path you want to store the models to and exit Ollama then restart Ollama server.