How to Fix the Issue of Extra Rows of Bad Data being created When Loading a Folder of CSV Files into Power BI:
Recently, I encountered an issue while working on a data project that involved loading millions of rows of data from a folder of CSV files into Power BI. During the process, I noticed that extra rows, which did not exist in the original files, were being generated. Here are the details (this is a demo project, and all sensitive information has been removed for confidentiality):
Testing with a Single CSV File
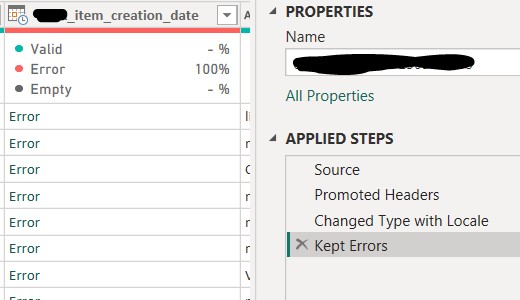
To troubleshoot and demonstrate the issue quickly, I started by testing with a single CSV file. Upon loading this file into Power BI, I noticed an error in the “Creation_date” column. The error affected less than 1% of the rows, showing an “Error” message in that column.
Initially, I assumed it was a common issue with formatting datetime values in Power BI. To resolve it, I attempted the three standard methods for converting the column to a datetime format. However, the error persisted despite these efforts.
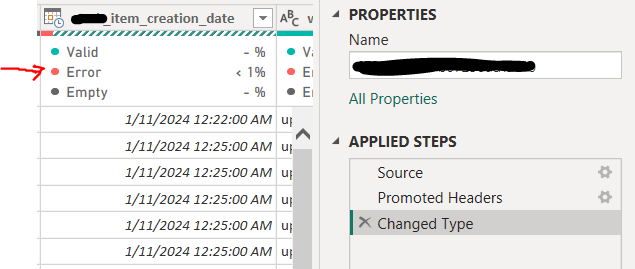
Then, I filtered the column to display only the rows with "Error," but this didn't provide much insight into the root cause of the issue.